
ChatGPT 的工作原理是尝试理解您的提示,然后根据训练的数据输出它预测最能回答您问题的字符串。

让我们实际谈谈这次培训。在这个过程中,新生的人工智能被赋予了一些基本规则,然后它要么被置于情境中,要么被赋予大量数据来处理,以开发自己的算法。
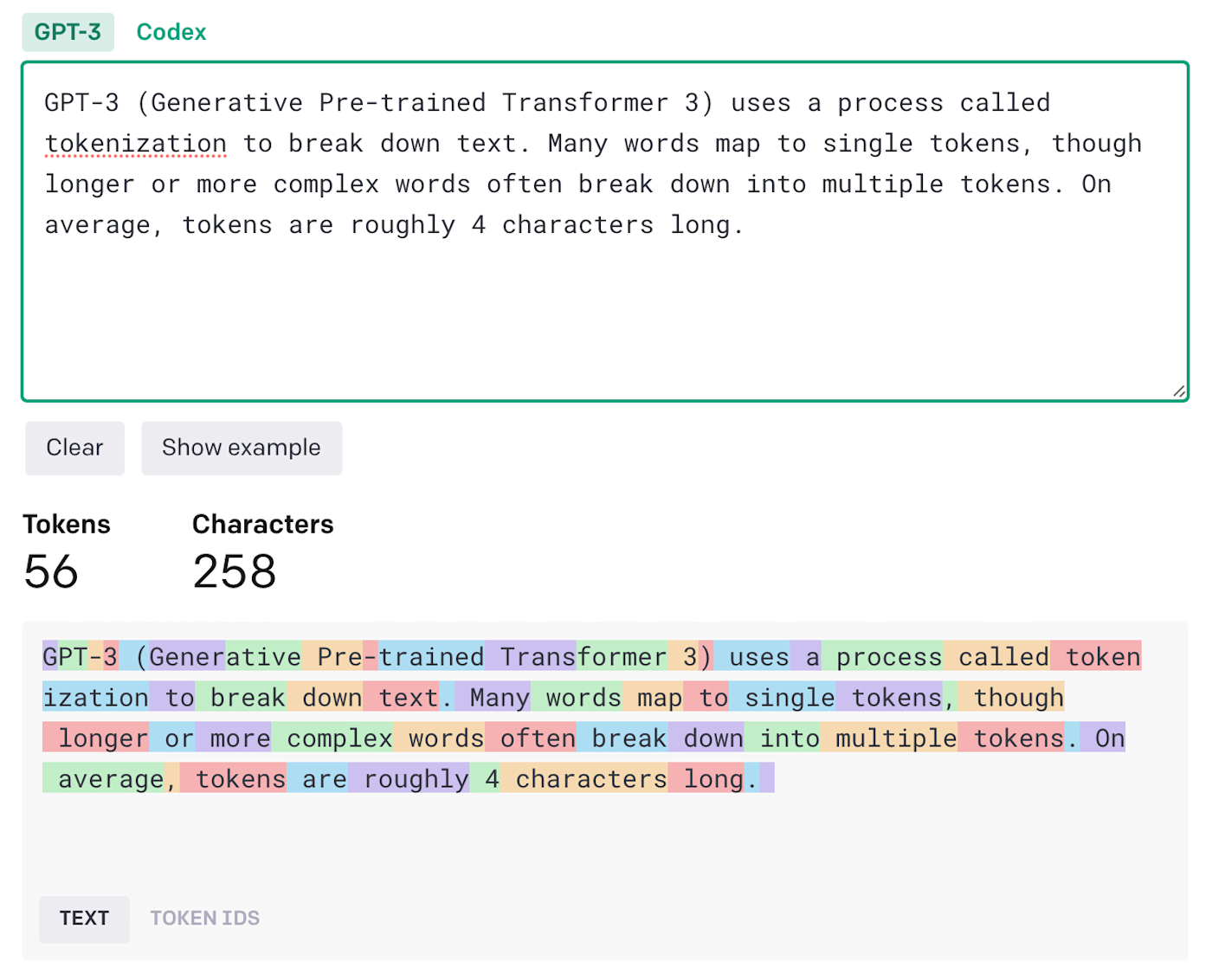
GPT-3 接受了大约 5000 亿个“标记”的训练,这使得它的语言模型能够更轻松地分配含义并预测看似合理的后续文本。许多单词映射到单个标记,但较长或更复杂的单词通常会分解为多个标记。平均而言,令牌的长度大约为四个字符。OpenAI 对 GPT-4 的内部运作保持沉默,但我们可以放心地假设它是在几乎相同的数据集上进行训练的,因为它更强大。
所有代币都来自人类编写的海量数据集。其中包括涵盖所有不同主题、风格和流派的书籍、文章和其他文档,以及从开放互联网上抓取的数量令人难以置信的内容。基本上,它被允许处理人类知识的总和。
这个庞大的数据集被用来形成一个深度学习神经网络——一种模仿人脑的复杂、多层、加权算法——它使得 ChatGPT 能够学习文本数据中的模式和关系,并利用创建类人数据的能力。通过预测任何给定句子中接下来应该出现的文本来做出响应。
但实际上,这大大低估了东西的价值。ChatGPT 不适用于句子级别,相反,它会生成可能跟随的单词、句子甚至段落或节的文本。这不是你手机上的预测文本直接猜测下一个单词;而是直接猜测下一个单词。它试图对任何提示创建完全连贯的响应。
为了进一步完善 ChatGPT 响应各种不同提示的能力,它使用一种称为人类反馈强化学习 (RLHF) 的技术针对对话进行了优化。从本质上讲,人类通过比较数据创建了一个奖励模型(其中两个或多个模型响应由人工智能培训师进行排名),因此人工智能可以了解哪个是最佳响应。
图片来自ChatGPT
回到它形成的神经网络。基于所有这些训练,GPT-3 的神经网络拥有 1750 亿个参数或变量,允许它接受输入(您的提示),然后根据它赋予不同参数的值和权重(以及少量的随机性) ),输出它认为最符合您的请求的任何内容。OpenAI 没有透露 GPT-4 有多少参数,但可以肯定地猜测,它超过 1750 亿个,比曾经传闻的100万亿个参数要少。无论确切的数字是多少,参数越多并不意味着越好。GPT-4 增强的能力部分可能来自于比 GPT-3 拥有更多的参数,但很大程度上可能归功于其训练方式的改进。
最后,最简单的想象方式就像你小时候玩的“说完句子”游戏之一。
最后,最简单的想象方式就像你小时候玩的“说完句子”游戏之一。例如,当我使用 GPT-3 向 ChatGPT 发出提示“Zapier 是……”时,它回复说:
“Zapier 是一款基于 Web 的自动化工具,允许用户将不同的 Web 应用程序连接在一起,以便自动执行重复任务并改进工作流程。”
您可以在数百篇描述 Zapier 所做工作的文章中找到这种句子,因此它在这里吐出这样的内容是有道理的。但当我的编辑给出同样的提示时,它说:
“Zapier 是一款基于 Web 的自动化工具,允许用户连接不同的 Web 应用程序并自动化它们之间的工作流程。”
这非常相似,但并不完全相同。这种随机性(您可以在某些 GPT-3 应用程序中使用名为“温度”的设置进行控制)确保 ChatGPT 不仅仅以相当于库存答案的方式响应每个响应。它每次都会在整个神经网络中运行每个提示,并到处掷骰子以保持新鲜感。它不太可能开始声称 Zapier 是来自火星的颜色,但它会根据以下单词的相对可能性来混合它们。
(就其价值而言,当在 GPT-4 上运行时,ChatGPT 表示:“ Zapier 是一个基于 Web 的自动化工具,允许用户在各种在线应用程序和服务之间集成和自动化任务。”几乎相同!)
吐出的是言语,不是知识
ChatGPT 的制造者首先表示它可能会产生不正确(并且可能有害)的信息,尽管他们正在努力修复它。
这是一个简单的例子。当我要求 ChatGPT 使用 GPT-3 和 GPT-4 回复“Harry Guinness 是……”时,GPT-3 首先回答是询问哪个 Harry Guinness。好问题——我们实际上有两个人!所以我说,“作家哈利·吉尼斯”(就是我)。GPT-4 立刻猜出了我是谁,尽管这两个回答都很有趣:
GPT-3: Harry Guinness 是爱尔兰的自由作家和记者。他曾为多种出版物撰稿,包括《纽约时报》、《卫报》、《赫芬顿邮报》和《大众机械》。他的主题涵盖从技术和摄影到旅行和文化。
GPT-4:Harry Guinness 是一位爱尔兰作家、摄影师和技术专家。他曾为多种出版物撰写文章,包括 How-To Geek、Lifehacker 和 Tuts+。他的工作主要侧重于技术、教程和技巧,以及摄影和图像编辑。吉尼斯因创建详细指南而享有盛誉,这些指南可以帮助读者理解复杂的主题或以简单的方式解决问题。
GPT-3 的第一行和最后一行几乎是从我的各个网站和网络上的作者简介中逐字提取的(尽管我通常将自己列为自由作家和摄影师,而不是记者)。但出版物的清单基本上都是编出来的。我曾为《纽约时报》撰稿,但没有为《卫报》、《赫芬顿邮报》或《大众机械》撰稿(我确实定期为《大众科学》撰稿,所以这可能就是来源)。
GPT-4 正确地描述了摄影师的部分,并实际上列出了我为之撰写的一些出版物,这令人印象深刻,尽管它们不是我最引以为豪的出版物。这是 OpenAI 如何提高 GPT-4 相对于 GPT-3 的准确性的一个很好的例子,尽管它可能并不总是提供最正确的答案。
但让我们回到 GPT-3,因为它的错误提供了一个有趣的例子,说明 ChatGPT 幕后发生的事情。它实际上对我一无所知。它甚至不是从互联网复制/粘贴并信任信息来源。相反,它只是根据其拥有的数十亿个数据点来预测接下来出现的一串单词。
例如:《纽约时报》经常与《卫报》和《赫芬顿邮报》归为一类,而不是与我为之撰写文章的地方(例如《连线》、《Outside》、《爱尔兰时报》,当然还有 Zapier)归为一类。因此,当它必须确定《纽约时报》应该跟进什么时,它不会从已发布的有关我的信息中提取信息;而是从我的信息中获取信息。它从拥有的所有训练数据中提取大型出版物的列表。这很聪明,看起来也很有道理,但事实并非如此。
GPT-4 做得更好,并且钉住了出版物,但它所说的其余内容实际上只是感觉像是看似合理的后续句子。我不认为它对我的声誉有任何高度的赞赏:它只是说了一些简历所说的事情。尽管它实际上使用了大致相同的技术,但它在隐藏其工作原理方面比 GPT-3 更好。
尽管如此,GPT 的改进还是令人印象深刻。目前,GPT-4 被锁定在高级订阅之后,因此您看到的大多数 ChatGPT 内容将依赖于 GPT-3,但这种情况可能会在接下来的一段时间内发生变化。谁知道 GPT-5 会带来什么。

相关文章
