
纵观所有非常大的卷积神经网络,例如 ResNet、VGG 等,这就引出了一个问题:我们如何使用更少的参数使所有这些网络变得更小,同时仍然保持相同的精度水平,甚至提高泛化能力。模型使用较少的参数。一种方法是深度可分离卷积,也称为 TensorFlow 和 Pytorch 中的可分离卷积(不要与空间可分离卷积混淆,空间可分离卷积也称为可分离卷积)。深度可分离卷积由 Sifre 在“用于图像分类的刚性运动散射”中引入,并已被流行的模型架构(例如 MobileNet 和 Xception 中的类似版本)采用。
在本教程中,我们将了解什么是深度可分离卷积以及如何使用它们来加速我们的卷积神经网络图像模型。
完成本教程后,您将学到:
- 什么是深度、逐点、深度可分离卷积
- 如何在 Tensorflow 中实现深度可分离卷积
- 将它们用作我们计算机视觉模型的一部分
让我们开始吧!

概述
本教程分为 3 部分:
- 什么是深度可分离卷积
- 为什么它们有用
- 在计算机视觉模型中使用深度可分离卷积
什么是深度可分离卷积
在深入研究深度方向和深度可分离卷积之前,快速回顾一下卷积可能会有所帮助。图像处理中的卷积是在体积上应用内核的过程,其中我们使用权重作为内核的值对像素进行加权和。视觉上如下:
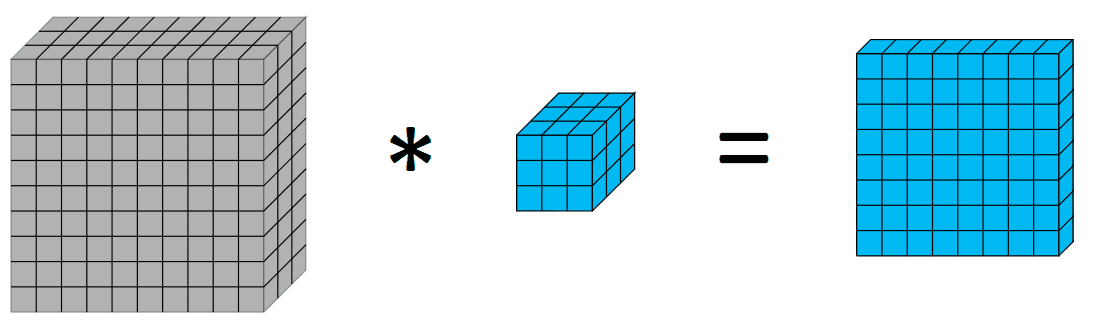
在 10x10x3 上应用 3×3 内核会输出 8x8x1 体积
现在,我们来介绍深度卷积。深度卷积基本上是仅沿着图像的一个空间维度的卷积。从视觉上看,这就是单个深度卷积滤波器的外观和功能:
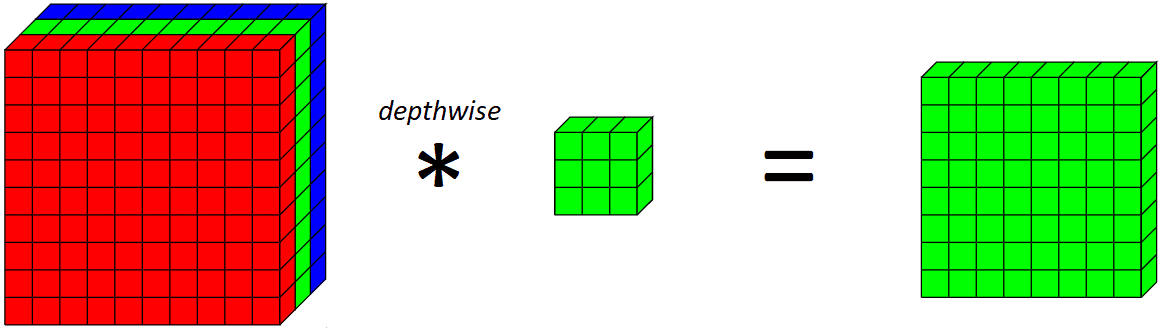
3x3在此示例中,在绿色通道上应用深度内核
普通卷积层和深度卷积之间的主要区别在于,深度卷积仅沿一个空间维度(即通道)应用卷积,而普通卷积在每一步都应用于所有空间维度/通道。
如果我们看看整个深度层在所有 RGB 通道上的作用,
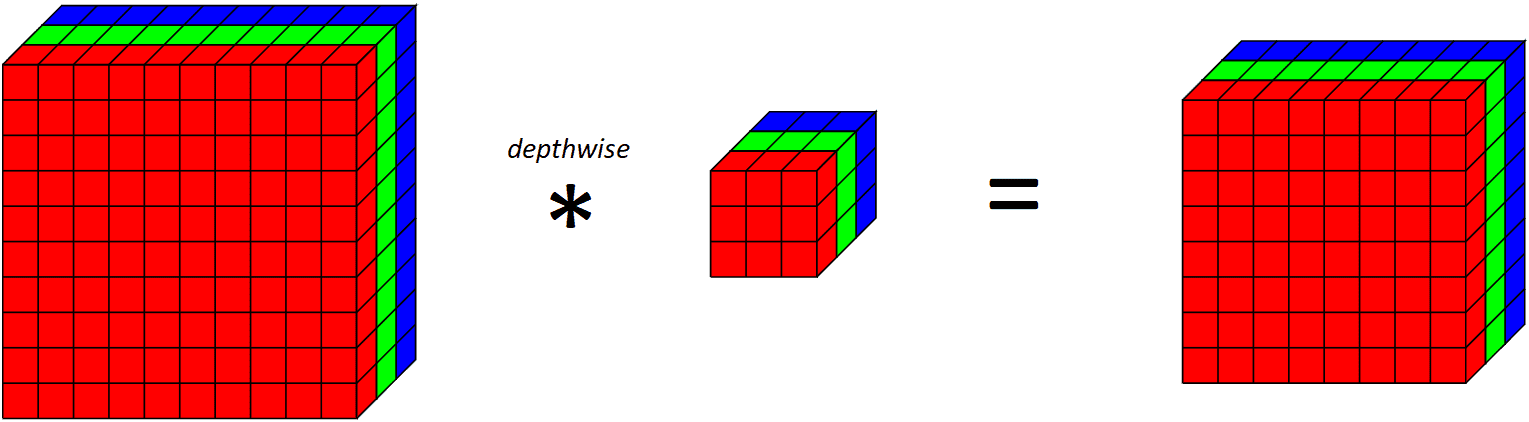
10x10x3对输入体积输出8x8x3体积应用深度卷积滤波器
请注意,由于我们为每个输出通道应用一个卷积滤波器,因此输出通道的数量等于输入通道的数量。应用深度卷积层后,我们再应用逐点卷积层。
简单地说,逐点卷积层是具有内核的常规卷积层1x1(因此查看所有通道上的单个点)。从视觉上看,它看起来像这样:

10x10x3对输入体积应用逐点卷积10x10x1输出输出体积
为什么深度可分离卷积有用?
现在,您可能想知道,使用深度可分离卷积进行两个操作有什么用?鉴于本文的标题是加速计算机视觉模型,那么执行两项操作而不是一项操作如何有助于加快速度?
为了回答这个问题,让我们看看模型中的参数数量(尽管进行两次而不是一次卷积会产生一些额外的开销)。假设我们想要对 RGB 图像应用 64 个卷积滤波器,以便在输出中拥有 64 个通道。普通卷积层的参数数量(包括偏差项)为$3 \times 3 \times 3 \times 64 + 64 = 1792$。另一方面,使用深度可分离卷积层只会有 $(3 \times 3 \times 1 \times 3 + 3) + (1 \times 1 \times 3 \times 64 + 64) = 30 + 256 = 286 $ 参数,这是一个显着的减少,深度可分离卷积的参数不到普通卷积的 6 倍。3×3×3×64+64=1792年。另一方面,使用深度可分离卷积层只会有(3×3×1×3+3)+(1×1×3×64+64)=30+256=第286章 参数,这是一个显着的减少,深度可分离卷积的参数不到普通卷积的 6 倍。
这有助于减少计算和参数的数量,从而减少训练/推理时间,并有助于分别规范我们的模型。
让我们看看实际情况。对于我们的输入,我们使用 CIFAR10 图像数据集32x32x3,
|
1
2
3
4
5
|
import tensorflow.keras as keras
from keras.datasets import mnist
# load dataset
(trainX, trainY), (testX, testY) = keras.datasets.cifar10.load_data()
|
然后,我们实现一个深度可分离卷积层。Tensorflow 中有一个实现,但我们将在最后一个示例中进行讨论。
|
1
2
3
4
5
6
7
8
9
|
class DepthwiseSeparableConv2D(keras.layers.Layer):
def __init__(self, filters, kernel_size, padding, activation):
super(DepthwiseSeparableConv2D, self).__init__()
self.depthwise = DepthwiseConv2D(kernel_size = kernel_size, padding = padding, activation = activation)
self.pointwise = Conv2D(filters = filters, kernel_size = (1, 1), activation = activation)
def call(self, input_tensor):
x = self.depthwise(input_tensor)
return self.pointwise(x)
|
使用深度可分离卷积层构建模型并查看参数数量,
|
1
2
3
4
|
visible = Input(shape=(32, 32, 3))
depthwise_separable = DepthwiseSeparableConv2D(filters=64, kernel_size=(3,3), padding=“valid”, activation=“relu”)(visible)
depthwise_model = Model(inputs=visible, outputs=depthwise_separable)
depthwise_model.summary()
|
这给出了输出
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_15 (InputLayer) [(None, 32, 32, 3)] 0
depthwise_separable_conv2d_ (None, 30, 30, 64) 286
11 (DepthwiseSeparableConv2
D)
=================================================================
Total params: 286
Trainable params: 286
Non–trainable params: 0
_________________________________________________________________
|
我们可以将其与使用常规 2D 卷积层的类似模型进行比较,
|
1
|
normal = Conv2D(filters=64, kernel_size=(3,3), padding=”valid”, activation=”relu”)(visible)
|
这给出了输出
|
1
2
3
4
5
6
7
8
9
10
11
12
|
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(None, 32, 32, 3)] 0
conv2d (Conv2D) (None, 30, 30, 64) 1792
=================================================================
Total params: 1,792
Trainable params: 1,792
Non–trainable params: 0
_________________________________________________________________
|
这证实了我们对之前完成的参数数量的初步计算,并显示了通过使用深度可分离卷积可以实现的参数数量的减少。
您现在可能会想,但它们为什么有效?
Chollet 的 Xception 论文中的一种思考方式是,深度可分离卷积假设我们可以单独映射跨通道和空间相关性。鉴于此,卷积层中将存在一堆冗余权重,我们可以通过将卷积分为深度分量和逐点分量的两个卷积来减少这些冗余权重。对于熟悉线性代数的人来说,思考这个问题的一种方法是,当矩阵中的列向量互为倍数时,我们如何能够将矩阵分解为两个向量的外积。
在计算机视觉模型中使用深度可分离卷积
现在我们已经看到了通过在普通卷积滤波器上使用深度可分离卷积可以实现的参数减少,让我们看看如何在实践中与 Tensorflow 的滤波器一起使用它SeparableConv2D。
对于本示例,我们将使用上例中使用的 CIFAR-10 图像数据集,而对于模型,我们将使用基于 VGG 块构建的模型。深度可分离卷积的潜力在于更深的模型,其中正则化效果对模型更有利,并且相对于 LeNet-5 等更轻的权重模型,参数的减少更明显。
使用 VGG 块和普通卷积层创建我们的模型,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Dense, Flatten, SeparableConv2D
import tensorflow as tf
# function for creating a vgg block
def vgg_block(layer_in, n_filters, n_conv):
# add convolutional layers
for _ in range(n_conv):
layer_in = Conv2D(filters = n_filters, kernel_size = (3,3), padding=‘same’, activation=“relu”)(layer_in)
# add max pooling layer
layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in)
return layer_in
visible = Input(shape=(32, 32, 3))
layer = vgg_block(visible, 64, 2)
layer = vgg_block(layer, 128, 2)
layer = vgg_block(layer, 256, 2)
layer = Flatten()(layer)
layer = Dense(units=10, activation=“softmax”)(layer)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
model.compile(optimizer=“adam”, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=“acc”)
history = model.fit(x=trainX, y=trainY, batch_size=128, epochs=10, validation_data=(testX, testY))
|
然后我们看看这个带有普通卷积层的6层卷积神经网络的结果,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
conv2d (Conv2D) (None, 32, 32, 64) 1792
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
max_pooling2d (MaxPooling2D (None, 16, 16, 64) 0
)
conv2d_2 (Conv2D) (None, 16, 16, 128) 73856
conv2d_3 (Conv2D) (None, 16, 16, 128) 147584
max_pooling2d_1 (MaxPooling (None, 8, 8, 128) 0
2D)
conv2d_4 (Conv2D) (None, 8, 8, 256) 295168
conv2d_5 (Conv2D) (None, 8, 8, 256) 590080
max_pooling2d_2 (MaxPooling (None, 4, 4, 256) 0
2D)
flatten (Flatten) (None, 4096) 0
dense (Dense) (None, 10) 40970
=================================================================
Total params: 1,186,378
Trainable params: 1,186,378
Non–trainable params: 0
_________________________________________________________________
Epoch 1/10
391/391 [==============================] – 11s 27ms/step – loss: 1.7468 – acc: 0.4496 – val_loss: 1.3347 – val_acc: 0.5297
Epoch 2/10
391/391 [==============================] – 10s 26ms/step – loss: 1.0224 – acc: 0.6399 – val_loss: 0.9457 – val_acc: 0.6717
Epoch 3/10
391/391 [==============================] – 10s 26ms/step – loss: 0.7846 – acc: 0.7282 – val_loss: 0.8566 – val_acc: 0.7109
Epoch 4/10
391/391 [==============================] – 10s 26ms/step – loss: 0.6394 – acc: 0.7784 – val_loss: 0.8289 – val_acc: 0.7235
Epoch 5/10
391/391 [==============================] – 10s 26ms/step – loss: 0.5385 – acc: 0.8118 – val_loss: 0.7445 – val_acc: 0.7516
Epoch 6/10
391/391 [==============================] – 11s 27ms/step – loss: 0.4441 – acc: 0.8461 – val_loss: 0.7927 – val_acc: 0.7501
Epoch 7/10
391/391 [==============================] – 11s 27ms/step – loss: 0.3786 – acc: 0.8672 – val_loss: 0.8279 – val_acc: 0.7455
Epoch 8/10
391/391 [==============================] – 10s 26ms/step – loss: 0.3261 – acc: 0.8855 – val_loss: 0.8886 – val_acc: 0.7560
Epoch 9/10
391/391 [==============================] – 10s 27ms/step – loss: 0.2747 – acc: 0.9044 – val_loss: 1.0134 – val_acc: 0.7387
Epoch 10/10
391/391 [==============================] – 10s 26ms/step – loss: 0.2519 – acc: 0.9126 – val_loss: 0.9571 – val_acc: 0.7484
|
让我们尝试相同的架构,但用 KerasSeparableConv2D层替换普通的卷积层:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# depthwise separable VGG block
def vgg_depthwise_block(layer_in, n_filters, n_conv):
# add convolutional layers
for _ in range(n_conv):
layer_in = SeparableConv2D(filters = n_filters, kernel_size = (3,3), padding=‘same’, activation=‘relu’)(layer_in)
# add max pooling layer
layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in)
return layer_in
visible = Input(shape=(32, 32, 3))
layer = vgg_depthwise_block(visible, 64, 2)
layer = vgg_depthwise_block(layer, 128, 2)
layer = vgg_depthwise_block(layer, 256, 2)
layer = Flatten()(layer)
layer = Dense(units=10, activation=“softmax”)(layer)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
model.compile(optimizer=“adam”, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=“acc”)
history_dsconv = model.fit(x=trainX, y=trainY, batch_size=128, epochs=10, validation_data=(testX, testY))
|
运行上面的代码给我们结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
separable_conv2d (Separab (None, 32, 32, 64) 283
leConv2D)
separable_conv2d_2 (Separab (None, 32, 32, 64) 4736
leConv2D)
max_pooling2d (MaxPoolin (None, 16, 16, 64) 0
g2D)
separable_conv2d_3 (Separab (None, 16, 16, 128) 8896
leConv2D)
separable_conv2d_4 (Separab (None, 16, 16, 128) 17664
leConv2D)
max_pooling2d_2 (MaxPoolin (None, 8, 8, 128) 0
g2D)
separable_conv2d_5 (Separa (None, 8, 8, 256) 34176
bleConv2D)
separable_conv2d_6 (Separa (None, 8, 8, 256) 68096
bleConv2D)
max_pooling2d_3 (MaxPoolin (None, 4, 4, 256) 0
g2D)
flatten (Flatten) (None, 4096) 0
dense (Dense) (None, 10) 40970
=================================================================
Total params: 174,821
Trainable params: 174,821
Non–trainable params: 0
_________________________________________________________________
Epoch 1/10
391/391 [==============================] – 10s 22ms/step – loss: 1.7578 – acc: 0.3534 – val_loss: 1.4138 – val_acc: 0.4918
Epoch 2/10
391/391 [==============================] – 8s 21ms/step – loss: 1.2712 – acc: 0.5452 – val_loss: 1.1618 – val_acc: 0.5861
Epoch 3/10
391/391 [==============================] – 8s 22ms/step – loss: 1.0560 – acc: 0.6286 – val_loss: 0.9950 – val_acc: 0.6501
Epoch 4/10
391/391 [==============================] – 8s 21ms/step – loss: 0.9175 – acc: 0.6800 – val_loss: 0.9327 – val_acc: 0.6721
Epoch 5/10
391/391 [==============================] – 9s 22ms/step – loss: 0.7939 – acc: 0.7227 – val_loss: 0.8348 – val_acc: 0.7056
Epoch 6/10
391/391 [==============================] – 8s 22ms/step – loss: 0.7120 – acc: 0.7515 – val_loss: 0.8228 – val_acc: 0.7153
Epoch 7/10
391/391 [==============================] – 8s 21ms/step – loss: 0.6346 – acc: 0.7772 – val_loss: 0.7444 – val_acc: 0.7415
Epoch 8/10
391/391 [==============================] – 8s 21ms/step – loss: 0.5534 – acc: 0.8061 – val_loss: 0.7417 – val_acc: 0.7537
Epoch 9/10
391/391 [==============================] – 8s 21ms/step – loss: 0.4865 – acc: 0.8301 – val_loss: 0.7348 – val_acc: 0.7582
Epoch 10/10
391/391 [==============================] – 8s 21ms/step – loss: 0.4321 – acc: 0.8485 – val_loss: 0.7968 – val_acc: 0.7458
|
请注意,深度可分离卷积版本中的参数明显较少(~200k vs~1.2m 参数),并且每个周期的训练时间略短。深度可分离卷积更有可能在可能面临过拟合问题的更深模型上以及在具有较大内核的层上工作得更好,因为参数和计算量的减少更大,这将抵消进行两次卷积而不是一次卷积的额外计算成本。接下来,我们绘制两个模型的训练和验证以及准确性,以查看模型训练性能的差异:

具有普通卷积层的网络的训练和验证准确性
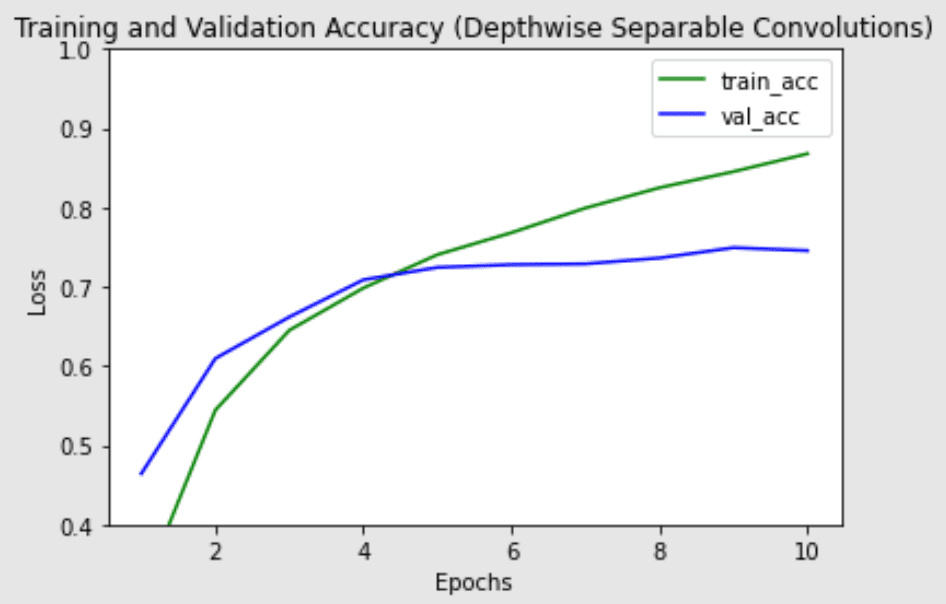
具有深度可分离卷积层的网络的训练和验证准确性
两种模型的最高验证精度相似,但深度可分离卷积似乎对训练集的过度拟合较少,这可能有助于它更好地推广到新数据。
将所有代码组合在一起以获得模型的深度可分离卷积版本,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import tensorflow.keras as keras
from keras.datasets import mnist
# load dataset
(trainX, trainY), (testX, testY) = keras.datasets.cifar10.load_data()
# depthwise separable VGG block
def vgg_depthwise_block(layer_in, n_filters, n_conv):
# add convolutional layers
for _ in range(n_conv):
layer_in = SeparableConv2D(filters = n_filters, kernel_size = (3,3), padding=‘same’,activation=‘relu’)(layer_in)
# add max pooling layer
layer_in = MaxPooling2D((2,2), strides=(2,2))(layer_in)
return layer_in
visible = Input(shape=(32, 32, 3))
layer = vgg_depthwise_block(visible, 64, 2)
layer = vgg_depthwise_block(layer, 128, 2)
layer = vgg_depthwise_block(layer, 256, 2)
layer = Flatten()(layer)
layer = Dense(units=10, activation=“softmax”)(layer)
# create model
model = Model(inputs=visible, outputs=layer)
# summarize model
model.summary()
model.compile(optimizer=“adam”, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=“acc”)
history_dsconv = model.fit(x=trainX, y=trainY, batch_size=128, epochs=10, validation_data=(testX, testY))
|
相关文章
